La pasada semana, in un examen, me preguntaron cuál era el mejor punto para una prueba diagnóstica; era necesario razonar mi respuesta. Seguramente mi respuesta fue correcta, pero mi razonamiento no lo fue y por eso quería redimirme. Para evaluar las pruebas diagnósticas con una respuesta binaria (sí/no), contamos con la sensibilidad y la especificidad. La sensibilidad es la capacidad que tiene la prueba para acertar sobre los que de verdad tiene que acertar (la probabilidad de etiquetar como enfermos a aquellos que verdaderamente están enfermos). La especificidad es una medida que nos indica cuánto nos hemos equivocado con los «unos» (la probabilidad de etiquetar enfermos a pacientes sanos). Una forma de medir cuánto acertamos y cuánto nos equivocamos con nuestra prueba. Para analizar el comportamiento de nuestra prueba diagnóstica, debemos determinar un punto de corte. Para ilustrar cómo seleccionar el mejor punto de corte, vamos a emplear unos datos sacados de la web de bioestadística del Hospital Ramón y Cajal y vamos a elaborar una curva ROC con R y ggplot2.
La curva ROC es una representación gráfica de la sensibilidad y $1 - \text{especificidad}$. ROC es el acrónimo de Receiver Operating Characteristic. Es un método para valorar cómo está funcionando nuestro método diagnóstico, cuánto mejor es si lo comparamos con el azar. El azar diría que tenemos las mismas probabilidades de tener cualquier tipo de diagnóstico; es decir, pintamos una línea recta del punto $(0,0)$ al punto $(1,1)$: eso es el puro azar. In la red tenéis mucha literatura al respecto de divulgadores mejores que yo.
Ejemplo que habíamos comentado: evaluación del volumen corpuscular medio (VCM) en el diagnóstico de anemia ferropénica. Se usa como «patrón de oro» la existencia de depósitos de hierro en la médula ósea. Introducimos los datos mediante la lectura más sencilla (no son muchos):
sin_fe <- scan()
52 58 62 65 67 68 69 71 72 72 73 73
74 75 76 77 77 78 79 80 80 81 81 81 82 83
84 85 85 86 88 88 90 92
sin_fe <- data.frame(medida = sin_fe, Fe = rep(0, length(sin_fe)))
con_fe <- scan()
60 66 68 69 71 71 73 74 74 74 76 77
77 77 77 78 78 79 79 80 80 81 81 81 82 82
83 83 83 83 83 83 83 84 84 84 84 85 85 86
86 86 87 88 88 88 89 89 89 90 90 91 91 92
93 93 93 94 94 94 94 96 97 98 100 103
con_fe <- data.frame(medida = con_fe, Fe = rep(1, length(con_fe)))
datos <- rbind(sin_fe, con_fe)
Para analizar la sensibilidad y la especificidad de nuestra prueba, tenemos que establecer unos puntos de corte y elaborar para cada punto de corte una tabla $2 \times 2$ de este modo:
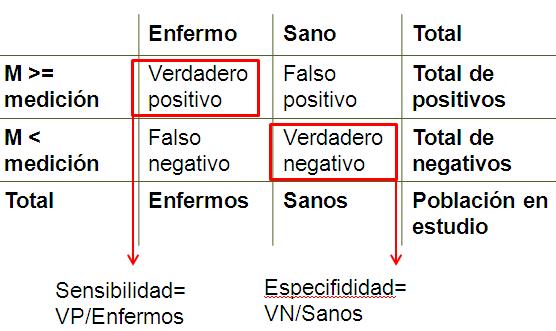
Vamos a realizar una tabla $2 \times 2$ para todos los puntos de corte de la medida del VCM que van desde 60 hasta 95; almacenamos in un objeto los valores de la sensibilidad y la especificidad para posteriormente poder realizar la representación gráfica:
puntos <- seq(60, 95, by = 5)
resultados <- data.frame()
for (i in puntos) {
tabla_2.2 <- table(ifelse(datos$medida >= i, 1, 0), datos$Fe)
# Manejo de casos donde la tabla no es 2x2
sensibilidad <- tabla_2.2[1, 1] / sum(datos$Fe == 0)
especificidad <- tabla_2.2[2, 2] / sum(datos$Fe == 1)
resultados <- rbind(resultados, data.frame(corte = i,
sensibilidad = sensibilidad,
uno_menos_especificidad = 1 - especificidad))
}
Los resultados obtenidos con nuestra prueba quedan tabulados del siguiente modo:
| corte | sensibilidad | uno_menos_especificidad |
|---|---|---|
| 60 | 0.0588 | 0.0000 |
| 65 | 0.0882 | 0.0152 |
| 70 | 0.2059 | 0.0606 |
| 75 | 0.3824 | 0.1515 |
| 80 | 0.5588 | 0.2879 |
| 85 | 0.7941 | 0.5606 |
| 90 | 0.9412 | 0.7424 |
| 95 | 1.0000 | 0.9242 |
library(ggplot2)
ggplot(resultados, aes(x = uno_menos_especificidad, y = sensibilidad)) +
geom_line() +
geom_abline(intercept = 0, slope = 1, colour = "red") + # Corrected escaping for "red"
theme_minimal()
La primera variable son los puntos de corte seleccionados, la segunda la sensibilidad y la tercera $1 - \text{especificidad}$. Así pues, si graficamos sensibilidad frente a $1 - \text{especificidad}$, tenemos la curva ROC:
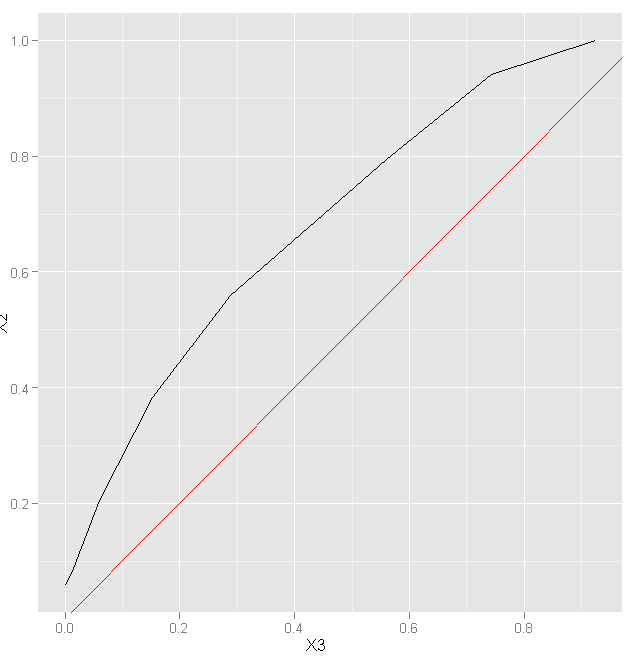
Pintamos la curva ROC para los puntos de corte establecidos. Y ahora viene el punto en el que me redimo de la contestación del examen que hice, que seguro que suspenderé porque mis problemas de memoria son bastante graves. El punto de corte óptimo es aquel donde es máxima la diferencia $\text{sensibilidad} - (1 - \text{especificidad})$. Es decir, donde menos errores cometemos a la hora de hacer el diagnóstico y donde menos etiquetamos de forma incorrecta a los que no tienen la enfermedad; donde mejor separamos. Aquí ya me equivoqué en el examen, pero además es muy importante determinar para qué estamos empleando nuestro análisis. Todo lo que está escrito arriba no sirve de nada si no sabemos el objeto del análisis.
¿Para qué estamos haciendo la prueba? Si estamos identificando aquellos pacientes que tienen un cáncer, me importa menos la especificidad; si etiqueto falsos positivos, me da lo mismo: es más importante identificar aquellos pacientes que tienen cáncer. In otro sector, si estoy haciendo un modelo de fraude, ojo con los falsos positivos: puedo estar perdiendo una oportunidad de negocio por etiquetar como operaciones fraudulentas aquellas que no lo son. Elegir el punto de corte no es un problema de optimización; no me habléis de «punto óptimo», habladme del mejor punto para nuestros objetivos.
Voy a suspender por no haber contado este rollo… Saludos.