Para un tema de mi trabajo voy a utilizar una regresión de Poisson en vez de una regresión logística; el evento es sí o no y no tiene nada que ver el tiempo, ni se puede contabilizar como un número, pero a efectos prácticos es mejor para mí usar una regresión de Poisson. Entonces, ¿qué pasa si hago una regresión de Poisson en vez de binomial? Como siempre, si mi $n$ es muy grande hay relación entre ambas distribuciones. Pero yo quiero saber si me puede clasificar mis registros igual una regresión logística, una de Poisson y una binomial, y se me ha ocurrido hacer un ejercicio teórico muy simple.
Construyo con SAS 10.000 datos aleatorios con las variables independientes x e y normalmente distribuidas y la variable dependiente z que es una función logística “perfecta” de x e y:
data logistica;
do i = 1 to 10000;
x = rannor(8);
y = rannor(2);
prob = 1 / (1 + exp(-(-10 + 5 * x - 5 * y)));
z = ranbin(8, 1, prob);
output;
end;
drop i;
run;
data entrenamiento test;
set logistica;
if ranuni(6) > 0.8 then output test;
else output entrenamiento;
run;
proc freq data=entrenamiento;
tables z;
run;
Separo los datos en entrenamiento y test y vemos que un 8% aproximadamente de mis registros tienen valor 1. Sobre estos datos hago una logística y una Poisson y veo los parámetros:
proc logistic data=entrenamiento;
model z = x y;
run;
proc genmod data=entrenamiento;
model z = x y / dist = poisson link = log scale = deviance;
run;
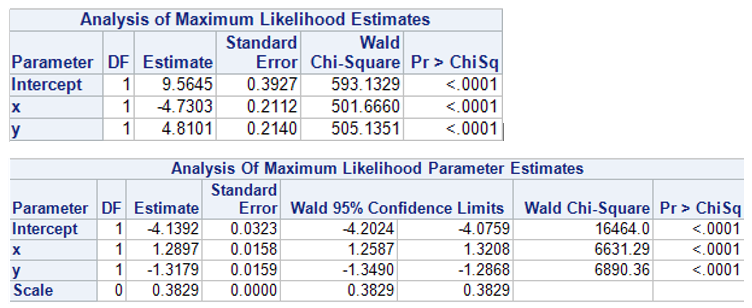
Los parámetros no tienen por qué parecerse, claro, pero sí me gustaría que observarais que tienen signo contrario, un apunte. Ahora, tal cual me han salido, hacemos un scoring sobre los datos de test y dividimos en 10 tramos por esas variables de scoring:
data test;
set test;
prob_logistica = 1 / (1 + exp(-(-9.5645 + 4.7303 * x - 4.8101 * y)));
num_poisson = exp(-4.1392 + 1.2897 * x - 1.3179 * y);
run;
proc rank data=test out=test2 groups=10;
var prob_logistica;
ranks rank_logistica;
run;
proc rank data=test2 out=test2 groups=10;
var num_poisson;
ranks rank_poisson;
run;
Creo el scoring “a lo mecagüen”, como le gusta decir a mi amigo Juan, y en otro dataset tengo las variables prob_logistica y num_poisson resultantes del scoring divididas en 10 tramos; si hacemos una tabla de frecuencias de estas dos variables obtenemos:
proc freq data=test2;
tables rank_logistica * rank_poisson / nocol norow nopercent;
run;
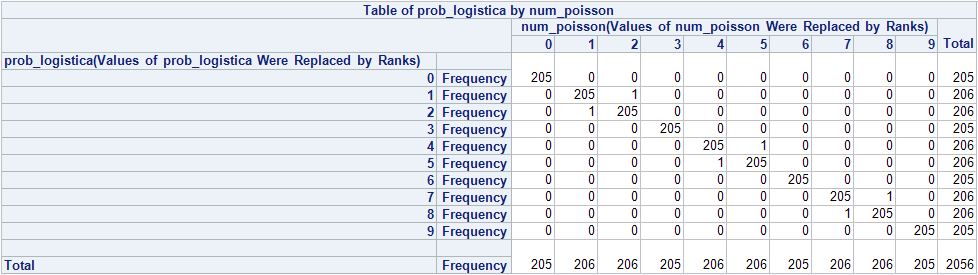
Resulta que obtenemos prácticamente lo mismo, así que puedo usar la regresión de Poisson en vez de la binomial y hablar de proporciones en vez de probabilidades, algo que explica mejor mi problema. Saludos.