Debemos de ir introduciendo el concepto de Social Pricing en el sector asegurador; si recordamos el año pasado, Admiral y Facebook tuvieron un tira y afloja por el uso de la información de Facebook para el ajuste de primas de riesgo. Facebook alegaba a la sección 3.15 de su privacidad para no permitir emplear esta información a Admiral. Probablemente es un tema más económico. El caso es que tanto Facebook como Instagram, Twitter, LinkedIn, xVideos… tienen información muy interesante acerca de nosotros, información que se puede emplear para el cálculo de primas en el sector asegurador (por ejemplo).
No voy a decir cómo hacer esto; este blog no es el lugar; el que quiera conocer mis ideas, que se ponga en contacto conmigo. Yo soy alguien “público”, no tengo problema en dejar mis redes sociales abiertas y este caso me sirve de ejemplo para analizar qué dice Twitter de mí y también sirve de ejemplo para refrescar el manejo de información con Twitter con #rstats. Esta entrada es una combinación de entradas anteriores de esta bitácora, así que recordemos cómo empezábamos a hacer scraping de Twitter:
library(twitteR)
library(base64enc)
consumer_key <- "XXXXXXXXXxxxxXXXXXXXxx"
consumer_secret <- "xxXXXXXXXXxxXXXXXXXXXxxXXxxxxx"
access_token <- "81414758-XXxXxxxx"
access_secret <- "XXXxXXxXXxxxxx"
setup_twitter_oauth(consumer_key, consumer_secret, access_token = access_token, access_secret = access_secret)
Vía OAuth ya podemos trabajar con el paquete twitteR desde nuestra sesión de R y ahora lo que vamos a crear es un objeto R del tipo user con la información que tiene el usuario r_vaquerizo (yo mismo):
rvaquerizo <- getUser('r_vaquerizo')
rvaquerizo_seguidos <- rvaquerizo$getFriends(retryOnRateLimit = 120)
seguidos <- do.call("rbind", lapply(rvaquerizo_seguidos, as.data.frame))
El objeto rvaquerizo tiene mucha información sobre mí, pero nos interesan los usuarios que sigo y para ello se emplea el método getFriends con el que creamos un data frame. Ahora vamos a seleccionar las descripciones de los usuarios de Twitter a los que sigo; el campo description tiene esa información. Ahora ya podemos trabajar con las palabras que describen a mis seguidos con un código que será familiar a los seguidores más antiguos:
# La lista la transformamos en un texto
texto <- toString(seguidos$description)
# El texto lo transformamos en una lista separada por espacios
texto_split <- strsplit(texto, split = " ")
# Deshacemos esa lista y tenemos el data frame
texto_col <- as.character(unlist(texto_split))
texto_col <- data.frame(V1 = toupper(texto_col))
# Eliminamos algunos caracteres regulares
texto_col$V1 <- gsub("([[:space:]])", "", texto_col$V1)
texto_col$V1 <- gsub("([[:digit:]])", "", texto_col$V1)
texto_col$V1 <- gsub("([[:punct:]])", "", texto_col$V1)
# Creamos una variable longitud de la palabra
texto_col$largo <- nchar(texto_col$V1)
# Quitamos palabras cortas
texto_col <- subset(texto_col, largo > 4 & largo <= 10)
Ahora sólo queda pintar las palabras que describen a los usuarios que sigo:
# install.packages('wordcloud')
library(wordcloud)
library(RColorBrewer)
pesos <- data.frame(table(texto_col$V1))
# Paleta de colores
pal <- brewer.pal(6, "RdYlGn")
# Realizamos el gráfico
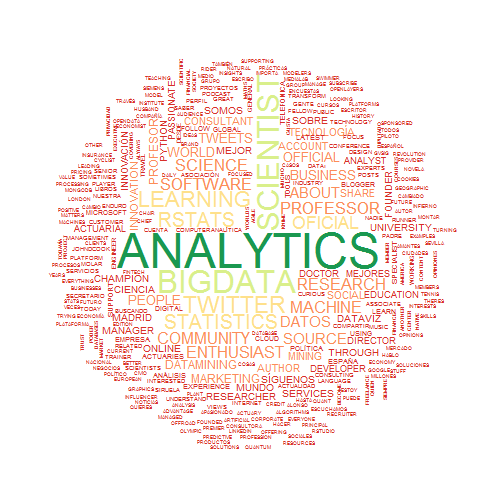
png('C:\\temp\\rvaquerizo.png', width = 500, height = 500)
wordcloud(pesos$Var1, pesos$Freq, scale = c(4, .2), min.freq = 2,
max.words = Inf, random.order = FALSE, colors = pal, rot.per = .15)
dev.off()
“Analytics” es el término más repetido; aparecen “Big Data”, “scientist”… ¿describen esos términos a un buen conductor o a alguien que cuida mucho su hogar? Yo sé la respuesta, pero sería necesario realizar un análisis con mayor número de expuestos. ¿Alguien se atreve a hacerlo?
Por cierto, yo quiero ser el Data Scientist de xVideos, cómo se tiene que reír.