La regresión no lineal se da cuando tenemos que estimar $Y$ a partir de una función del tipo $Y = f(X, \beta) + \epsilon$, donde $\beta$ representa un vector de parámetros $\beta_1, \beta_2, \dots, \beta_n$. Unos datos $X$ e $Y$ se relacionan mediante una función no lineal respecto a unos parámetros $\beta$ desconocidos.
¿Cómo obtenemos estos $\beta$ desconocidos? Habitualmente a través de mínimos cuadrados ordinarios o bien con otros métodos como máxima verosimilitud. Este cálculo llevará asociada su inferencia estadística habitual. La función que asocia los pares de datos $(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)$ será una función conocida. Por eso esta técnica es muy utilizada en ciencias químicas, geodinámica… donde ya se conoce la relación teórica que hay entre las variables, pero es necesario realizar modelos con los pares de datos disponibles de cara a obtener estimaciones de los parámetros.
Para la realización de este monográfico con R vamos a emplear el conjunto de datos Thurber. Son datos de un estudio del NIST sobre movilidad de electrones en semiconductores; la variable respuesta es la movilidad del electrón ($y$) y la variable regresora es el logaritmo de la densidad ($x$). El modelo propuesto es:
$$y = \frac{\beta_1 + \beta_2 x + \beta_3 x^2 + \beta_4 x^3}{1 + \beta_5 x + \beta_6 x^2 + \beta_7 x^3}$$
Nuestra variable está relacionada con su regresora por un modelo racional con siete parámetros. Comenzamos el trabajo con los datos en R:
# Datos de movilidad de electrones
y <- c(80.574, 84.248, 87.264, 87.195, 89.076, 89.608, 89.868,
90.101, 92.405, 95.854, 100.696, 101.06, 401.672, 390.724,
567.534, 635.316, 733.054, 759.087, 894.206, 990.785, 1090.109,
1080.914, 1122.643, 1178.351, 1260.531, 1273.514, 1288.339,
1327.543, 1353.863, 1414.509, 1425.208, 1421.384, 1442.962,
1464.35, 1468.705, 1447.894, 1457.628)
x <- c(-3.067, -2.981, -2.921, -2.912, -2.84, -2.797,
-2.702, -2.699, -2.633, -2.481, -2.363, -2.322, -1.501, -1.46,
-1.274, -1.212, -1.1, -1.046, -0.915, -0.714, -0.566, -0.545,
-0.4, -0.309, -0.109, -0.103, 0.01, 0.119, 0.377, 0.79, 0.963,
1.006, 1.115, 1.572, 1.841, 2.047, 2.2)
# Representación de los datos
plot(y ~ x, xlab = "Log de Densidad", ylab = "Movilidad de los electrones")
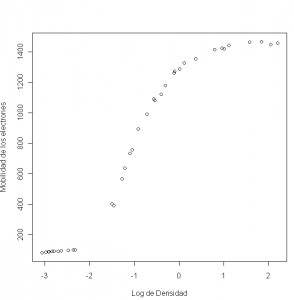
Metemos los datos directamente en R. Realizamos una representación gráfica y se aprecia la inexistencia de relación lineal. Introduzcamos en R la función racional:
foo <- function(x, b1, b2, b3, b4, b5, b6, b7) {
(b1 + b2*x + b3*x^2 + b4*x^3) / (1 + b5*x + b6*x^2 + b7*x^3)
}
El trabajo con R lo vamos a llevar a cabo con la función nls() del paquete stats. Pero antes de crear un modelo de regresión no lineal tenemos que asignar unos valores iniciales a los parámetros $\beta$. La regresión no lineal es un proceso iterativo: se parte de unos parámetros iniciales, se modeliza y, mediante un proceso de optimización numérica (como el algoritmo de Gauss-Newton), se aproximan los parámetros a los valores óptimos.
Para obtener los valores iniciales es necesario conocer los datos. En nuestro caso, para $x = 0$ el valor de $y$ ha de ser muy próximo a 1200, luego ese es un buen inicio para b1. Podemos emplear la librería nls2 para encontrar estos valores iniciales mediante “fuerza bruta”:
# install.packages("nls2")
library(nls2)
# Buscamos valores iniciales (esto es solo un ejemplo de planteamiento)
m1 <- nls2(y ~ foo(x, b1, b2, b3, b4, b5, b6, b7),
start = c(b1 = 1200, b2 = 100, b3 = 100, b4 = 1, b5 = -0.1, b6 = 0.1, b7 = -0.1),
control = nls.control(warnOnly = TRUE))
En este ejemplo concreto, partimos de valores conocidos para que el proceso converja:
# Valores iniciales razonables
start_vals <- c(b1 = 1000, b2 = 1000, b3 = 400, b4 = 40,
b5 = 0.7, b6 = 0.3, b7 = 0.03)
m.nls <- nls(y ~ foo(x, b1, b2, b3, b4, b5, b6, b7),
start = start_vals, trace = TRUE)
summary(m.nls)
El algoritmo ha necesitado iteraciones para converger. Ahora es necesario realizar un diagnóstico del modelo. Comenzamos por graficar el ajuste:
plot(y ~ x, xlab = "Log de Densidad", ylab = "Movilidad de los electrones",
main = "Ajuste del modelo nls")
lines(x, fitted(m.nls), col = "blue", lwd = 2)
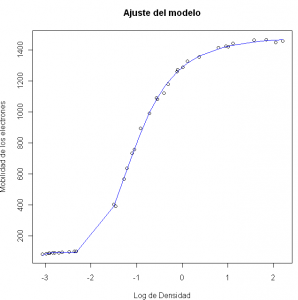
Gráficamente el modelo ajusta bien. Podemos ver la suma del cuadrado de los residuos con la función deviance():
deviance(m.nls)
# [1] 5642.708
También es necesario analizar si el modelo cumple las hipótesis estadísticas (normalidad de residuos, independencia, etc.). El test ANOVA nos permite comparar el ajuste frente a un modelo lineal simple:
# Anova para contraste de falta de ajuste
m.lm <- lm(y ~ x)
anova(m.nls, m.lm)
# Independencia de los residuos
plot(fitted(m.nls), residuals(m.nls),
xlab = "Valores ajustados", ylab = "Residuos")
abline(h = 0, col = "red", lty = 2)
# Test de normalidad de los residuos
qqnorm(residuals(m.nls))
qqline(residuals(m.nls))
shapiro.test(residuals(m.nls))
# Intervalos de confianza para los parámetros
confint(m.nls)
Ya disponemos de las herramientas de R para comenzar a trabajar con este tipo de modelos no lineales. También recomiendo ver las posibilidades de la librería nlstools. Saludos.