Hace pocas fechas vimos el código SAS empleado para la realización de ordenaciones de conjuntos de datos SAS mediante algoritmos de hash. Ya os comuniqué que era una forma más eficiente, y hoy quería demostraros tal eficiencia con un laboratorio de código SAS. La situación es la siguiente: creamos un dataset con 1.000.000 de registros y 13 variables, y comparamos un PROC SORT con una ordenación mediante objetos hash; medimos tiempos y determinamos qué método es más eficiente.
Si disponéis de una versión de SAS superior a la 9.1, me gustaría que ejecutarais las siguientes líneas. No es un código muy complejo, pero si alguien tiene dudas en su funcionamiento o le gustaría profundizar más, comentad el mensaje. El código para la realización de este experimento es el siguiente:
* DATASET DE PRUEBA PARA COMPARACION DE TIEMPOS;
data uno;
array v(10);
do i = 1 to 1000000;
importe = ranuni(mod(time(), 1) * 1000) * 10000;
do j = 1 to 5;
v(j) = ranuni(34) * 100;
end;
output;
end;
drop i j;
run;
* MACRO QUE AÑADE RESULTADOS AL DATASET DE TEST;
%macro aniade(descripcion);
data borra;
ejecucion = &i.;
metodo = "&descripcion.";
tiempo = time() - &inicio.;
output;
run;
data test;
set test borra;
run;
proc delete data=borra;
run;
%mend;
* MACRO QUE LANZA LA PRUEBA COMPARATIVA;
%macro test(ejecuciones);
%do i = 1 %to &ejecuciones.;
%let inicio = %sysfunc(time());
* MÉTODO 1: PROC SORT;
proc sort data=uno out=dos;
by importe;
run;
%if &i. = 1 %then %do;
data test;
ejecucion = &i.;
length metodo $20.;
metodo = "PROC SORT";
tiempo = time() - &inicio.;
output;
run;
%end;
%else %do;
%aniade(PROC SORT);
%end;
%let inicio = %sysfunc(time());
* MÉTODO 2: OBJETOS HASH;
data _null_;
if 0 then set uno;
declare hash obj (dataset: 'uno', hashexp: 20, ordered: 'a');
obj.defineKey('importe');
obj.defineData(all: 'YES');
obj.defineDone();
obj.output(dataset: 'dos_hash');
stop;
run;
%aniade(HASH);
%end;
%mend;
* LANZAMOS 10 EJECUCIONES;
%test(10);
* ORDENAMOS POR TIEMPO PARA VER RESULTADOS;
proc sort data=test;
by tiempo;
run;
proc print data=test;
run;
Para los que me seguís habitualmente, este código os resultará familiar. Me gustaría recalcar el uso de la opción HASHEXP (en este caso 20, que equivale a $2^{20}$ entradas en la tabla de hash). Veamos el resultado:
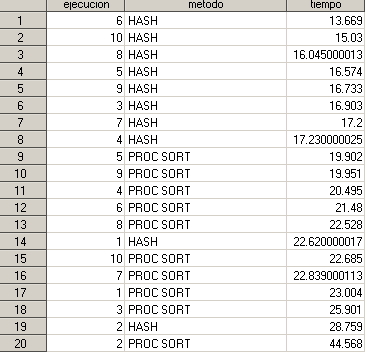
Las ordenaciones empleando este tipo de objetos son más rápidas. Sin embargo, replico el experimento modificando el exponente hashexp: 5 y me encuentro lo siguiente:
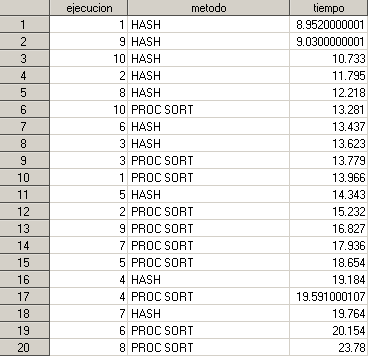
Mejoramos mucho el tiempo empleado para la ordenación; ésto implica que un exponente muy alto no garantiza siempre una mayor velocidad. Hemos de jugar con esta opción para optimizar el rendimiento. En determinadas circunstancias, incluso un PROC SORT puede ser más eficiente que hash si no empleamos un exponente correcto. Espero que estas líneas despierten vuestra curiosidad sobre estos algoritmos y permitan que vuestro trabajo diario sea más eficiente. Saludos.