La clasificación por k vecinos más cercanos es un método supervisado no paramétrico muy potente. El KNN (K-Nearest Neighbors) clasifica las observaciones en función de su proximidad a otros puntos en el espacio de características; en el vídeo que encabeza la entrada queda muy bien explicado.
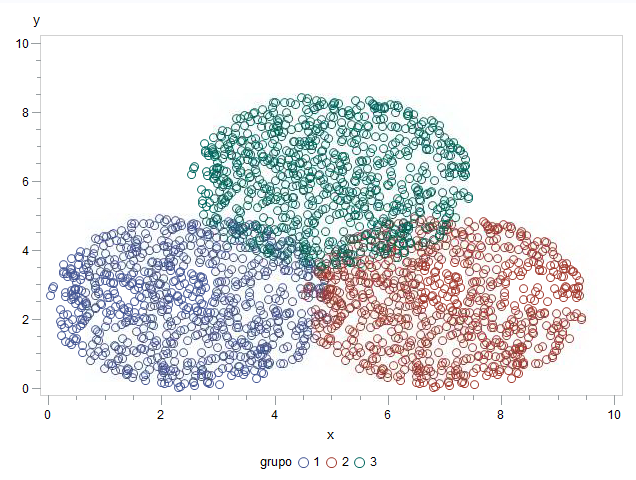
Tenemos la posibilidad de realizar esta clasificación con SAS/STAT y el PROC DISCRIM. Hace años ya hablamos de segmentación con SAS y vamos a emplear los mismos datos simulados de tres esferas para ilustrar esta entrada:
* GENERAMOS DATOS SIMULADOS;
data pelota;
do i = 1 to 1000;
x = 5 * ranuni(34);
y = 5 * ranuni(14);
distancia = sqrt(((x-2.5)**2) + ((y-2.5)**2));
if distancia < 2.5 then output;
end;
run;
data pelota1; set pelota; grupo=1; run;
data pelota2; set pelota; x = x + 4.5; grupo=2; run;
data pelota3; set pelota; x = x + 2.5; y = y + 3.5; grupo=3; run;
data datos;
set pelota1 pelota2 pelota3;
run;
proc gplot data=datos;
plot y * x = grupo;
run;
quit;
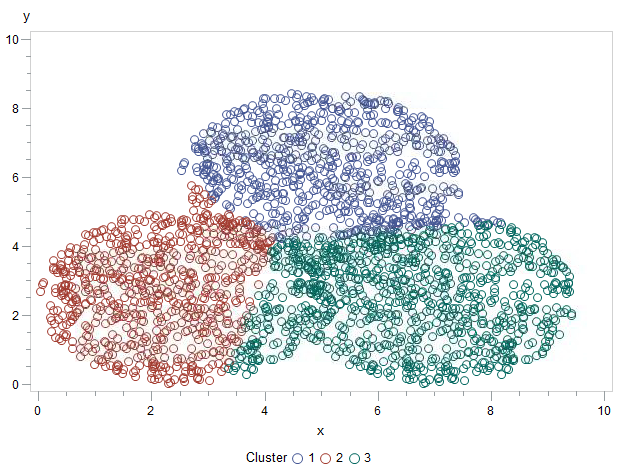
Si realizamos un análisis mediante K-Means (con PROC FASTCLUS) sin asignar centroides, podemos obtener una clasificación imperfecta debido a la asignación aleatoria inicial:
proc fastclus data=datos maxclusters=3 out=datos2;
var x y;
run;
proc gplot data=datos2;
plot y * x = cluster;
run;
quit;
Este problema lo podemos solventar empleando clasificación por KNN a partir del PROC DISCRIM:
data entreno testeo;
set datos;
if ranuni(7) >= 0.5 then output entreno;
else output testeo;
run;
proc discrim data=entreno test=testeo
testout=puntuacion method=npar k=5
crossvalidate;
class grupo;
var x y;
run;
proc gplot data=puntuacion;
plot y * x = _into_;
run;
quit;
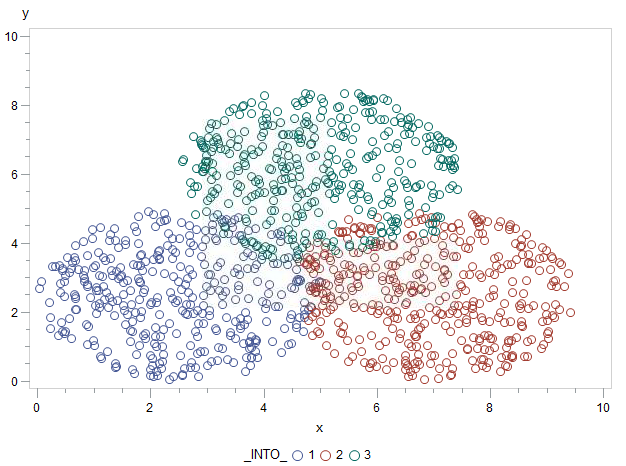
El resultado es muy satisfactorio. En method=npar especificamos que la clasificación la llevamos a cabo con un método no paramétrico y en ese momento necesitamos especificar la k, que es el número de vecinos que vamos a evaluar para clasificar cada observación.
Bajo mi punto de vista, KNN puede ayudarnos a seleccionar las semillas iniciales para una clasificación posterior por K-Means, obteniendo lo mejor de ambos mundos:
* OBTENEMOS CENTROIDES DEL KNN;
proc summary data=puntuacion nway;
class grupo;
output out=medias (keep=x y) mean(x)=x mean(y)=y;
run;
* USAMOS ESOS CENTROIDES COMO SEMILLAS;
proc fastclus data=datos maxclusters=3 out=datos3 seed=medias;
var x y;
run;
proc gplot data=datos3;
plot y * x = cluster;
run;
quit;
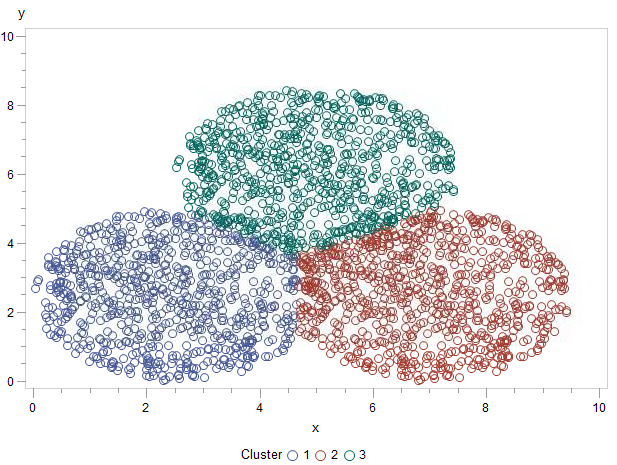
Este análisis sí arroja resultados muy precisos. Saludos.