Los capítulos 7 y 8 se resumen en éste mediante visualizaciones trabajadas en el capítulo 5. El análisis EDA (Exploratory Data Analysis) es el primer paso que ha de seguir un científico de datos y articula los temas tratados en el capítulo 2, ya que convertir datos en información implica que el analista ha de preocuparse en saber cómo están estructurados sus datos, qué tipo de variables los componen, el nivel al que se encuentran los registros, qué problemas pueden presentar o cómo resumir información. Además, es necesario conocer los capítulos 3 y 4 para el manejo de variables y cruces de tablas; por este motivo, el análisis EDA es la base, pero lo visto anteriormente son los cimientos.
Para realizar este tipo de análisis, R dispone de distintas librerías, algunas de ellas son:
Se sugiere que sea el propio científico de datos quien desarrolle sus propias herramientas descriptivas.
En este capítulo se empleará la librería DataExplorer por rapidez, sencillez de uso y fácil interpretación de la salida que ofrece. Se trabaja con el caso práctico de la campaña de venta cruzada de una empresa aseguradora.
library(tidyverse)
# Carga de datos
train <- read.csv("./data/train.csv")
head(train, 5)
El primer paso es conocer el número de observaciones y la naturaleza de las variables. Con DataExplorer comenzamos con la función introduce():
library(DataExplorer)
introduce(train)
Este análisis se puede acompañar de una visión gráfica:
plot_intro(train)
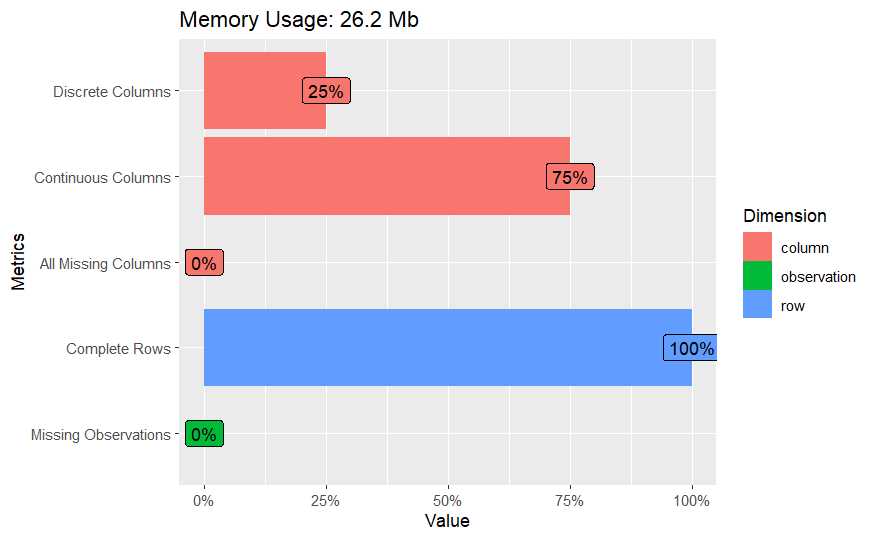
Disponemos de 381.109 observaciones y 12 variables donde un 25% son factores frente al 75% de numéricas. Todas las columnas están completas, por lo que no es necesaria una limpieza de valores perdidos. Observemos la estructura:
# Estructura de las variables
plot_str(train)
Se observa que hay variables como Previously_Insured, Region_Code o Policy_Sales_Channel que son numéricas pero deberían ser tratadas como factores. El siguiente paso es realizar histogramas para las variables numéricas con plot_histogram():
plot_histogram(train, ncol = 3)
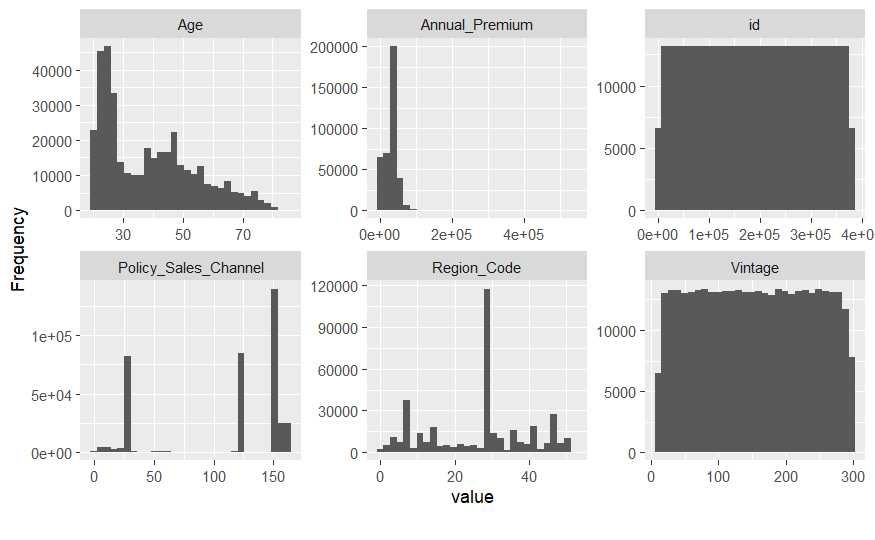
Analicemos algunas variables:
Age: Edad del encuestado, con moda en 25 años y un repunte a los 45.Annual_Premium: Prima anual concentrada en valores bajos con algunos valores extremos superiores a 40.000 €.Policy_Sales_ChannelyRegion_Code: Deben ser transformadas a factor.
train <- train %>%
mutate(Policy_Sales_Channel = as.character(Policy_Sales_Channel),
Region_Code = as.character(Region_Code))
Para analizar los factores, empleamos plot_bar():
plot_bar(train)
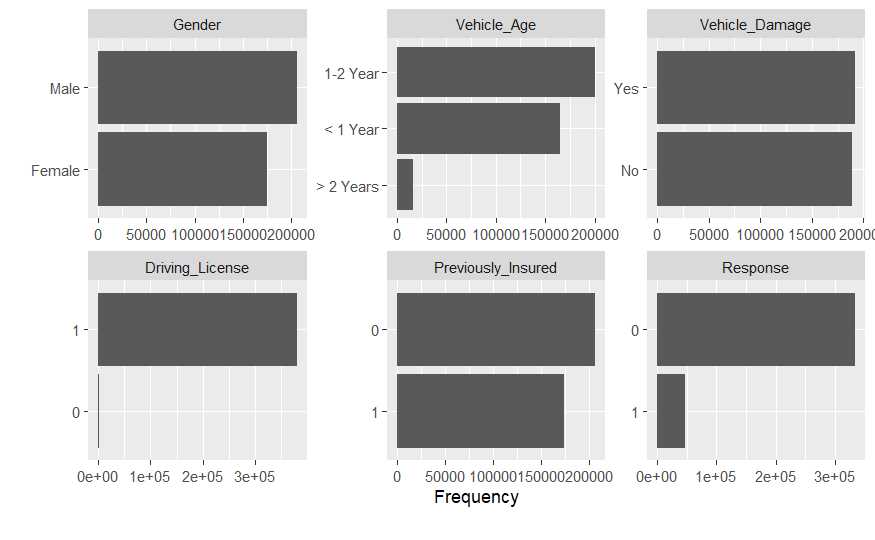
DataExplorer nos avisa de columnas con demasiadas categorías (como Region_Code). Estas variables son susceptibles de ser agrupadas. En cuanto al resto:
Vehicle_Age: El orden por defecto es lexicográfico (<1,1-2,>2), lo cual es incorrecto para el análisis cronológico.
Corregimos el orden de Vehicle_Age y aplicamos prefijos para identificar variables trabajadas (fr_ para factores):
train <- train %>%
mutate(fr_vehicle_age = factor(Vehicle_Age, levels = c('< 1 Year', '1-2 Year', '> 2 Years')))
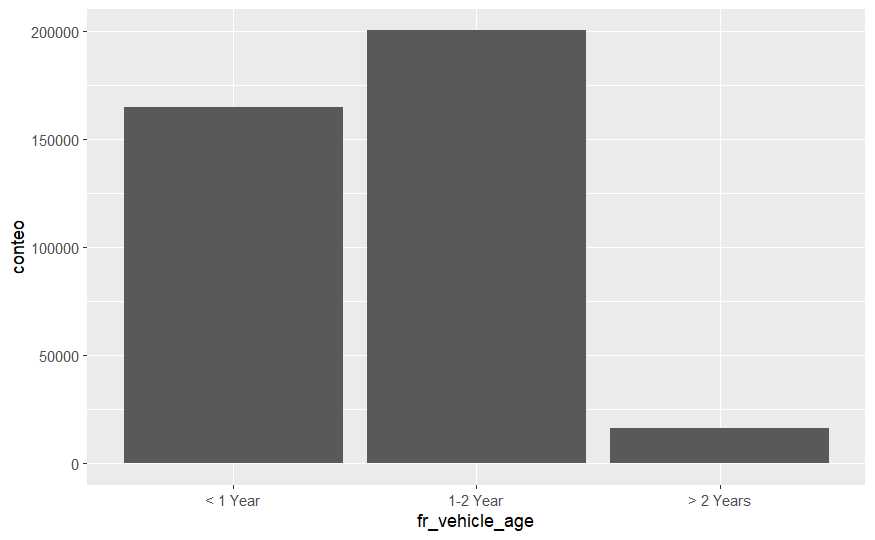
# Visualizamos el factor corregido
train %>%
group_by(fr_vehicle_age) %>%
summarise(conteo = n()) %>%
ggplot(aes(x = fr_vehicle_age, y = conteo)) +
geom_bar(stat = 'identity') +
theme_minimal()
Renombramos otros factores:
train <- train %>% rename(
fr_gender = Gender,
fr_vehicle_damage = Vehicle_Damage,
fr_previously_insured = Previously_Insured)
Para variables con muchos niveles como Region_Code, podemos sugerir agrupaciones basadas en el volumen (por ejemplo, destacar Madrid y Barcelona) o en el comportamiento de la variable respuesta.
El análisis EDA permite al científico de datos empezar a comprender la información disponible antes de pasar a la fase de modelización. La librería DataExplorer ofrece también la función create_report() para automatizar un reporte completo en HTML. Saludos.