Seguimos a vueltas con la (ya) pandemia y R, y hoy quería traeros unos buenos ejemplos de uso de dplyr para preparar datos. Se trata de ver una evolución del número de casos diarios para saber en qué punto tanto España como Italia pueden frenar el crecimiento de los casos de coronavirus; se trata de crear este gráfico:
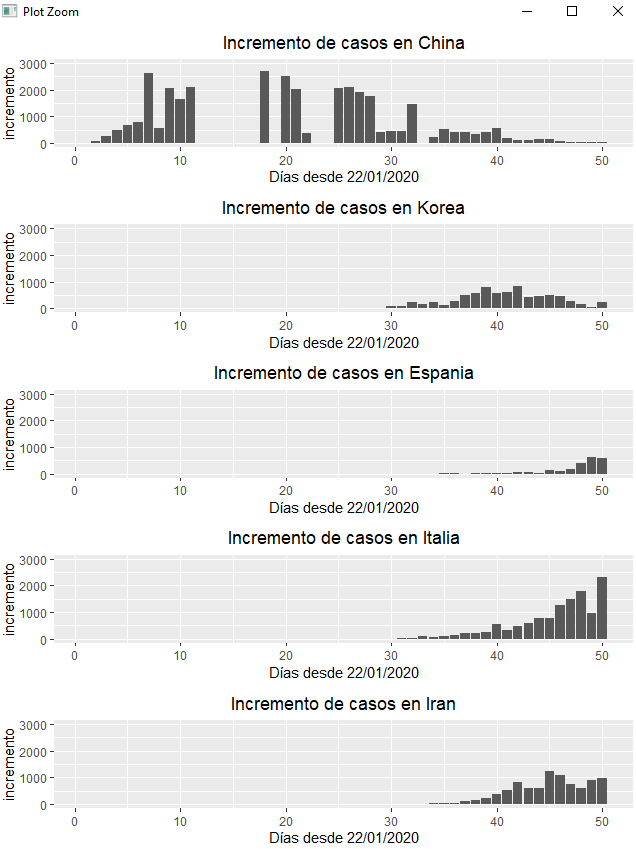
Se observa cómo países como China o Corea vivieron un fuerte crecimiento que ahora se ha transformado en una caída del número de casos de coronavirus, pero parece que Irán se ha estabilizado en 1000 casos diarios; mientras, Italia y España siguen en fase de crecimiento, por lo que no se espera que el comportamiento sea similar a China o Corea y es probable que el número de casos siga aumentando.
Para crear este gráfico estoy mejorando códigos que ya he venido utilizando y creo que son un buen ejemplo de uso de dplyr. El primer paso es crear el conjunto de datos inicial, código ya conocido:
library(lubridate)
library(ggplot2)
library(dplyr)
library(gridExtra)
datos <- read.csv2("https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv",
sep = ',')
fechas <- seq(as.Date("2020/01/22"), as.Date(today() - 1), "days")
fechas <- substr(as.character.Date(fechas), 6, 10)
names(datos) <- c("Provincia", "Pais", "Latitud", "Longitud", fechas)
Para ver los datos de China es necesaria una agregación previa, ya que China tiene los datos a nivel de región y no de país:
China <- filter(datos, Pais == "China")
China <- China %>% select(fechas)
China <- data.frame(casos = as.numeric(mapply(sum, China)))
China <- China %>% mutate(fecha = row.names(China), dias = row_number())
China2 <- China %>% mutate(dias = dias + 1) %>% rename(casos_menos1 = casos) %>% select(-fecha)
China <- left_join(China, China2) %>%
mutate(incremento = casos - casos_menos1,
incremento = case_when(is.na(incremento) ~ 0,
TRUE ~ incremento)) %>%
filter(dias <= 50)
Aquí es interesante el uso de mapply para sumar todas las columnas del conjunto de datos. Por otro lado, se trata de crear una variable incremento en función de los días que llevamos recogiendo datos; para ello lo que se hace es cruzar con los mismos datos pero sumamos un día al número de días de pandemia. De este modo, tenemos el dato del día y el dato del día anterior, por lo que podemos crear una variable incremento. Para el resto de países, como la información no está a nivel de región, hacemos una función:
select_pais <- function(pais, numdias) {
P <- filter(datos, Pais == pais) %>% select(fechas)
P <- P %>% mutate(fecha = row.names(P), dias = row_number())
P <- data.frame(casos = as.numeric(t(P)))
P <- P %>% mutate(fecha = row.names(P), dias = row_number())
P2 <- P %>% mutate(dias = dias + 1) %>% rename(casos_menos1 = casos) %>% select(-fecha)
P <- left_join(P, P2) %>%
mutate(incremento = casos - casos_menos1,
incremento = case_when(is.na(incremento) ~ 0,
TRUE ~ incremento)) %>%
filter(dias <= numdias)
return(P)
}
Korea <- select_pais('Korea, South', 50)
Iran <- select_pais('Iran', 50)
Italia <- select_pais('Italy', 50)
Espania <- select_pais('Spain', 50)
Ya tenemos los datos con la forma deseada. Ahora nos toca realizar un gráfico para cada país:
evolucion <- function(pais) {
df <- pais
df$incremento <- ifelse(df$casos <= 4, 0, df$incremento)
ggplot(df, aes(x = dias, y = incremento)) +
geom_bar(stat = "identity") +
scale_y_continuous(limits = c(0, 3000)) +
ggtitle(paste0('Incremento de casos en ', deparse(substitute(pais)))) +
theme(plot.title = element_text(hjust = 0.5)) +
xlab("Días desde 22/01/2020")
}
p1 = evolucion(China)
p2 = evolucion(Korea)
p3 = evolucion(Espania)
p4 = evolucion(Italia)
p5 = evolucion(Iran)
Una función que realiza un gráfico de barras con ggplot2 para cada país y tiene un uso interesante de la función deparse que junto con substitute nos permite poner en la función el nombre del data.frame y no los datos que contiene. Es una forma sencilla de obtener el nombre de un data.frame en una función. Si leéis que me reitero en algunas frases no os asustéis, sirve para facilitar búsquedas.
Ahora empleamos una librería que cambió mi vida, gridExtra, y podemos realizar el gráfico que abre esta entrada:
grid.arrange(p1, p2, p3, p4, p5, ncol = 1)
En este punto sólo queda ejecutar este código todos los días y esperar a que Italia y España lleguen a ese máximo. Saludos.