El sobremuestreo (oversampling) es una técnica de muestreo que se emplea habitualmente cuando tenemos una baja proporción de casos positivos en clasificaciones binomiales. Los modelos pueden “despreciar” los casos positivos por ser muy pocos y nuestro modelo no funcionaría. Para incrementar el número de casos positivos se emplea el sobremuestreo.
Ejemplos habituales pueden ser los modelos de fraude: un 99% de las compras son correctas y un 1% son fraudulentas. Si realizo un modelo sin tratar este desequilibrio, el algoritmo puede estar seguro al 99% de que todas las compras son correctas, ignorando el fraude. En este caso hemos de realizar un sobremuestreo para incrementar nuestros casos de fraude y poder detectar los patrones.
A mí particularmente me gusta realizar algunas pruebas exagerando la proporción para identificar aquellas variables que son más influyentes. No me quiero mojar mucho sobre la proporción ideal de casos positivos y negativos, pero si estamos realizando un nuevo muestreo podemos emplear perfectamente un 50% para ambos.
Sin embargo, cabe preguntarse: ¿mejora realmente la estimación un modelo con sobremuestreo?
Abrimos R y manos a la obra. Generamos datos simulados de una entidad bancaria que desea realizar un modelo para una campaña comercial sobre Pensiones Vitalicias Inmediatas (PVI):
clientes <- 20000
saldo_vista <- runif(clientes, 0, 1) * 10000
saldo_ppi <- (runif(clientes, 0.1, 0.6) * rpois(clientes, 2)) * 60000
saldo_fondos <- (runif(clientes, 0.1, 0.9) * (rpois(clientes, 1) - 0.5 > 0)) * 30000
edad <- rpois(clientes, 60)
datos_ini <- data.frame(saldo_vista, saldo_ppi, saldo_fondos, edad)
datos_ini$saldo_ppi <- (datos_ini$edad < 65) * datos_ini$saldo_ppi
# Creamos la variable objetivo a partir de un potencial teórico
potencial <- runif(clientes, 0, 1) + log(datos_ini$edad)/2 +
0.03 * (datos_ini$saldo_vista > 5000) +
0.09 * (datos_ini$saldo_fondos > 5000) +
0.07 * (datos_ini$saldo_ppi > 10000)
datos_ini$pvi <- as.factor((potencial >= quantile(potencial, 0.98)) * 1)
# Tabla de frecuencias: sólo un 2% de casos positivos
table(datos_ini$pvi)
Para nuestro estudio vamos a emplear regresión logística y árboles de decisión, pero lo primero es seleccionar una parte de las observaciones para validar los modelos:
# Subconjunto de validación
set.seed(123)
validacion <- sample(1:clientes, 5000)
entreno_full <- datos_ini[-validacion, ]
Vamos a generar una muestra con un 50% de casos positivos mediante la librería sampling:
# install.packages("sampling")
library(sampling)
# Muestra estratificada aleatoria con reemplazamiento
selec1 <- strata(entreno_full, stratanames = c("pvi"),
size = c(5000, 5000), method = "srswr")
entreno_over <- entreno_full[selec1$ID_unit, ]
Modelo de regresión logística
# Modelo sin sobremuestreo
modelo.1 <- glm(pvi ~ ., data = entreno_full, family = binomial)
# Modelo con sobremuestreo
modelo.2 <- glm(pvi ~ ., data = entreno_over, family = binomial)
¿Qué modelo funciona mejor? La librería ROCR nos permite realizar curvas ROC para medir el comportamiento:
library(ROCR)
# Validación del modelo sin sobremuestreo
valida_data <- datos_ini[validacion, ]
pred1_val <- predict(modelo.1, newdata = valida_data, type = "response")
pred_obj1 <- prediction(pred1_val, valida_data$pvi)
perf1 <- performance(pred_obj1, "tpr", "fpr")
# Validación del modelo con sobremuestreo
pred2_val <- predict(modelo.2, newdata = valida_data, type = "response")
pred_obj2 <- prediction(pred2_val, valida_data$pvi)
perf2 <- performance(pred_obj2, "tpr", "fpr")
# Pintamos ambas curvas ROC
plot(perf1, col = "blue", main = "Curvas ROC: Logística")
plot(perf2, col = "black", add = TRUE, lty = 2)
abline(a = 0, b = 1, col = "red")
legend("bottomright", legend = c("Sin sobremuestreo", "Con sobremuestreo"),
col = c("blue", "black"), lty = c(1, 2))
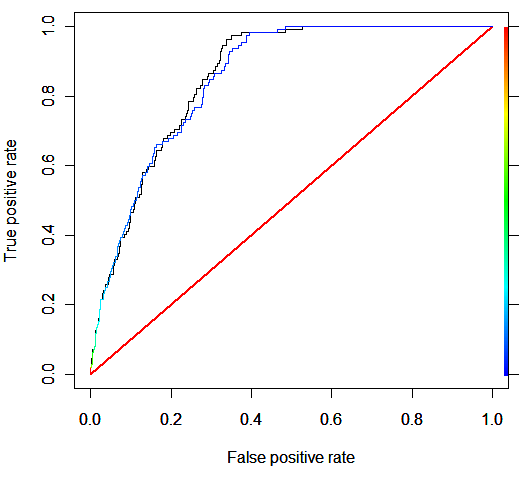
En este ejemplo, para la regresión logística, el modelo con sobremuestreo apenas mejora al modelo sin sobremuestreo.
Modelos con árboles de decisión
library(rpart)
# Modelo sin sobremuestreo
arbol.1 <- rpart(pvi ~ edad + saldo_ppi + saldo_fondos,
data = entreno_full, method = "class")
# Modelo con sobremuestreo
arbol.2 <- rpart(pvi ~ edad + saldo_ppi + saldo_fondos,
data = entreno_over, method = "class")
# Repetimos validación con ROCR (usando la probabilidad de la clase '1')
pred1_arbol <- predict(arbol.1, newdata = valida_data, type = "prob")[, 2]
pred2_arbol <- predict(arbol.2, newdata = valida_data, type = "prob")[, 2]
perf1_arbol <- performance(prediction(pred1_arbol, valida_data$pvi), "tpr", "fpr")
perf2_arbol <- performance(prediction(pred2_arbol, valida_data$pvi), "tpr", "fpr")
plot(perf1_arbol, col = "blue", main = "Curvas ROC: Árboles")
plot(perf2_arbol, col = "black", add = TRUE, lty = 2)
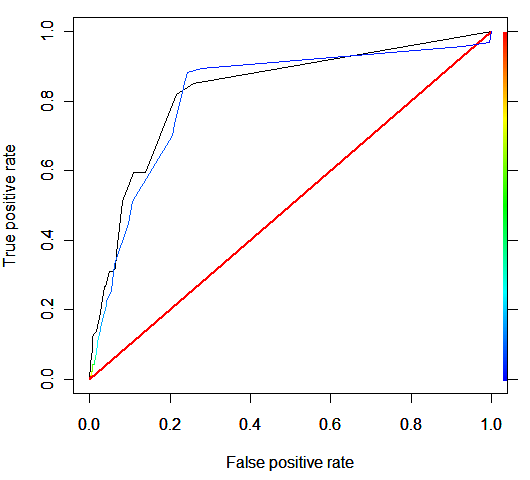
En este caso, las curvas ROC son distintas y el comportamiento del árbol varía sustancialmente. Os dejo que saquéis vuestras propias conclusiones.
Para evitaros problemas, os dejo en este enlace el código empleado para este experimento. Saludos.