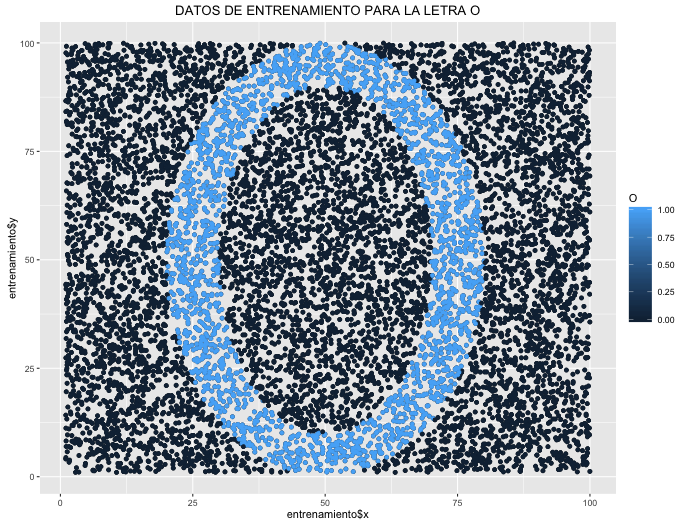
Cuando clasificamos datos con SVM (Support Vector Machines), es necesario fijar un margen de separación entre observaciones. Si no fijamos este margen adecuadamente, nuestro modelo podría estar sobrestimando (overfitting), lo que significa que funcionaría muy bien con los datos de entrenamiento pero fallaría con datos nuevos.
El coste C y el parámetro gamma son los dos elementos fundamentales con los que contamos en los SVM. El parámetro C es el peso que le damos a cada observación a la hora de clasificar: un mayor coste implicaría un mayor peso de cada observación individual y el SVM sería más estricto. Si tuviéramos un modelo que clasificara observaciones en el plano formando una letra “O”, podemos ver cómo se modifica la estimación al variar el coste:
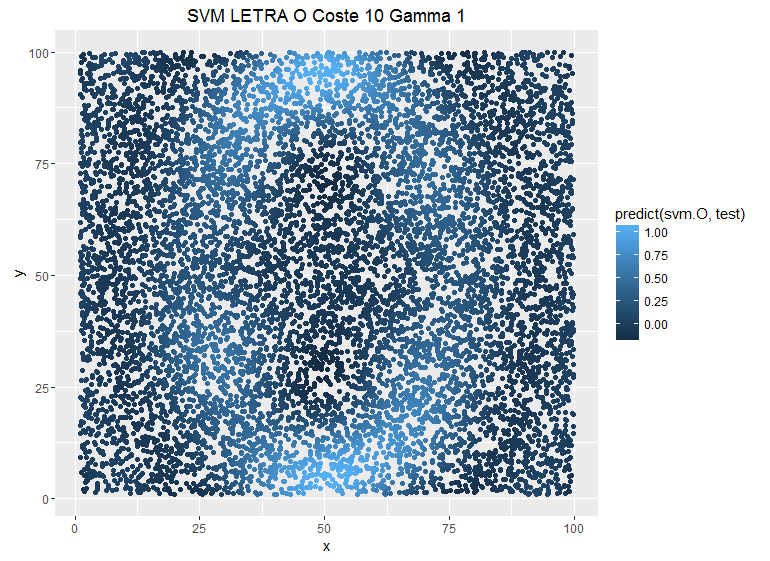
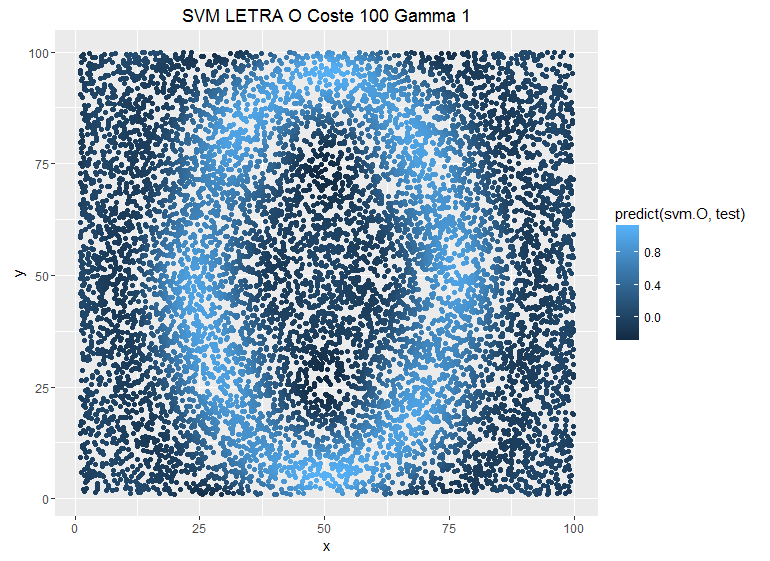
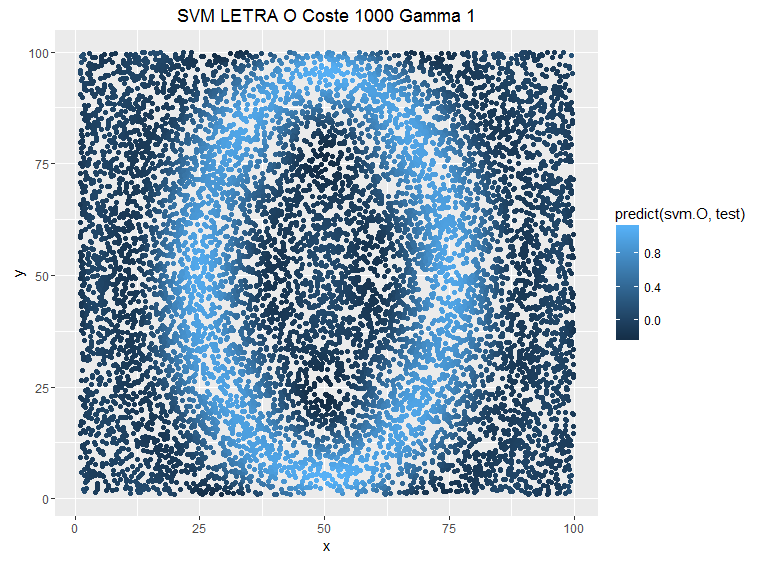
Se puede ver cómo la predicción es más conservadora cuando ponemos costes más bajos. Pero no es el único parámetro que tenemos para suavizar el modelo; también tenemos el parámetro gamma. Este parámetro define la influencia de un solo ejemplo de entrenamiento: valores bajos significan “lejos” y valores altos significan “cerca”. Con una función kernel radial, gamma determina la complejidad del límite de decisión.
Veamos el ejemplo anterior modificando el parámetro gamma y dejando fijo el coste C:
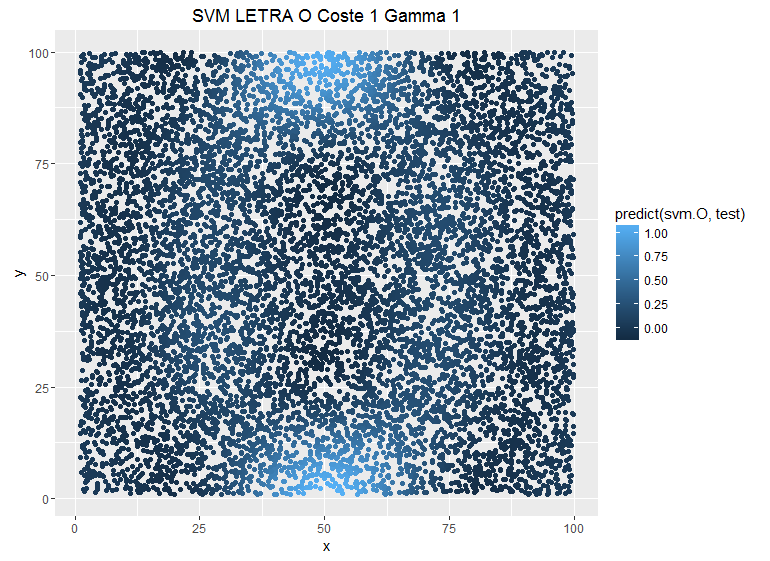
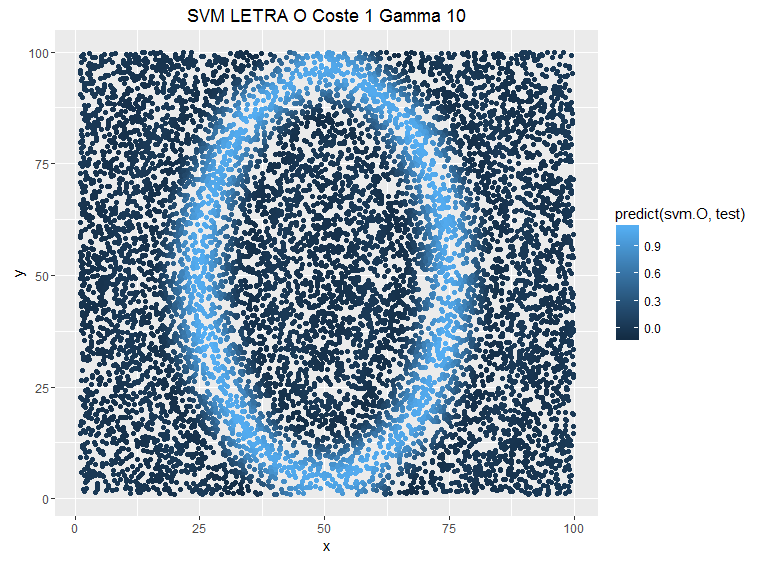
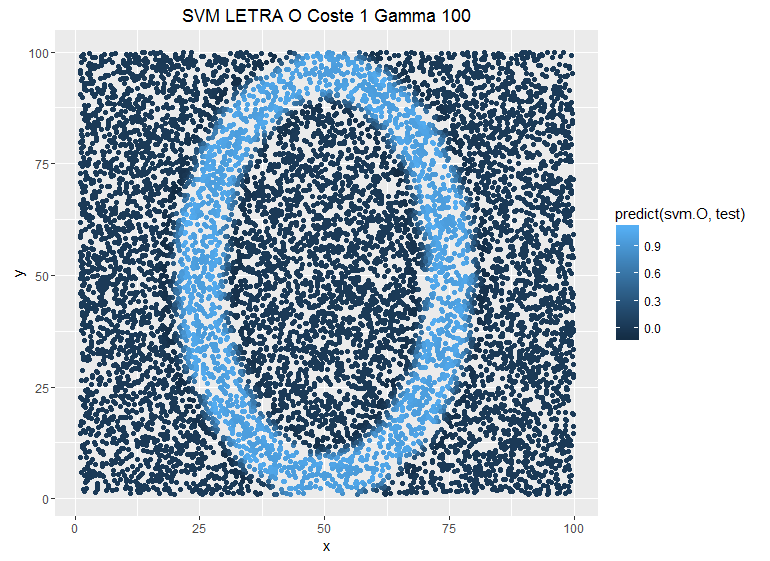
Un menor gamma implica una mayor suavidad en los subespacios del SVM, mientras que un mayor gamma añade complejidad y hace que el modelo se ajuste más a los puntos individuales. La función kernel habitual (RBF) se define como:
$$K(x, x’) = \exp(-\gamma ||x - x’||^2)$$
A mayor gamma, las predicciones están menos suavizadas. El reto está en encontrar el punto óptimo en el intercambio entre sesgo y varianza.
Todo este ejercicio está realizado con datos aleatorios en R empleando la librería e1071:
library(ggplot2)
library(e1071)
# Datos iniciales
long <- 20000
x <- runif(long, 1, 100)
y <- runif(long, 1, 100)
datos <- data.frame(x, y)
# Letra O en el entrenamiento
indices <- sample(1:long, long/2)
entrenamiento <- datos[indices, ]
test <- datos[-indices, ]
entrenamiento$O <- as.factor(ifelse((entrenamiento$x-50)^2/20^2 + (entrenamiento$y-50)^2/40^2 > 1, 1, 0))
entrenamiento$O <- as.factor(ifelse((entrenamiento$x-50)^2/30^2 + (entrenamiento$y-50)^2/50^2 > 1, 0, as.numeric(as.character(entrenamiento$O))))
# Gráfico de entrenamiento
ggplot(entrenamiento, aes(x, y, colour = O)) +
geom_point() +
labs(title = "DATOS DE ENTRENAMIENTO PARA LA LETRA O")
# Modelos SVM con diferentes parámetros
# Ejemplo con Coste 10 y Gamma 1
svm.O <- svm(O ~ x + y, data = entrenamiento, method = "C-classification",
kernel = "radial", cost = 10, gamma = 1)
# Predicción sobre el test
test$pred <- predict(svm.O, test)
ggplot(test, aes(x, y, colour = pred)) +
geom_point() +
labs(title = "SVM LETRA O Coste 10 Gamma 1")
Espero que estos ejemplos visuales ayuden a comprender el impacto de los hiperparámetros en los modelos SVM. Saludos.