Desde hace tiempo, mis frases son más cortas. Creo que es un problema de las redes sociales, sobre todo Twitter, que está cambiando mi comportamiento. Para analizar si esto está pasando, se me ha ocurrido analizar la longitud de las frases de este blog desde sus inicios y, de paso, aprovechar para hacer web scraping con la librería BeautifulSoup de Python. La idea es recorrer el blog, calcular la longitud de las frases y representar gráficamente cómo ha ido evolucionando esa longitud.
Podía haber trabajado directamente con la base de datos de WordPress, pero he preferido leer las páginas de la web. Hay un problema: si veis el nombre de las páginas, no tienen un orden cronológico, son el nombre de la propia entrada (por ejemplo, https://analisisydecision.es/los-bancos-lo-llaman-transformacion-digital-yo-lo-llamo-me-da-miedo-facebook/), pero es cierto que se almacena una vista por mes de las entradas publicadas (https://analisisydecision.es/2017/02/). Vamos a emplear esas vistas que no recogen la entrada entera, pero sí las primeras frases; con estas limitaciones vamos a medir la longitud de las frases.
Luego la analizamos paso a paso, pero la función de Python que voy a emplear es:
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
import time
import string
def extrae(anio, mes):
url = "https://analisisydecision.es/" + anio + "/" + mes + "/"
print(url)
# Realizamos la petición a la web
pagina = requests.get(url)
soup = BeautifulSoup(pagina.content, 'html.parser')
m = str(soup.find_all('p'))
m_soup = BeautifulSoup(m, 'html.parser')
text_content = m_soup.get_text()
frases = pd.DataFrame(text_content.split("."), columns=['frase'])
frases['largo'] = frases['frase'].str.len()
frases['mes'] = anio + mes
# Limpieza de puntuación
table = str.maketrans('', '', string.punctuation)
frases['frase'] = frases['frase'].apply(lambda x: x.translate(table))
frases = frases.loc[frases.largo > 10]
time.sleep(5) # Reducido para el ejemplo, pero ojo con el firewall
return frases
Os comento paso a paso: a la función le vamos a pasar el mes y el año, y esa será la URL que lee (https://analisisydecision.es/2017/02/); ésa es la web sobre la que vamos a hacer el scraping. Vía requests obtenemos la web y usamos BeautifulSoup para quedarnos con el contenido en HTML de la web cargada:
# Realizamos la petición a la web
pagina = requests.get(url)
soup = BeautifulSoup(pagina.content, 'html.parser')
En este punto tenemos un HTML y debemos saber qué nos interesa. Para el ejercicio, nos interesan los párrafos (las etiquetas <p>). Ojo, que puede interesarnos guardar alguna tabla u otro elemento; en nuestro estudio estamos analizando la longitud de las frases que hay en los párrafos, luego buscaremos las etiquetas <p>:
m = str(soup.find_all('p'))
m_soup = BeautifulSoup(m, 'html.parser')
Hemos pasado de un completo código HTML a sólo quedarnos con los párrafos; ahora, al limpiar el resto de código HTML, tendremos algo que podamos usar:
text_content = m_soup.get_text()
Soy un principiante en esto de Python y, por ese motivo, me encuentro más cómodo trabajando con data.frames:
frases = pd.DataFrame(text_content.split("."), columns=['frase'])
frases['largo'] = frases['frase'].str.len()
frases['mes'] = anio + mes
# Limpieza rudimentaria
frases = frases.loc[frases.largo > 10]
Creamos un data.frame con una sola variable que contendrá las frases extraídas en el proceso de scraping y le añadimos una variable largo, que será la que al final analicemos; además le añadimos la fecha en la que estamos extrayendo los datos para luego graficar por esa fecha. Ahora sólo hacemos una burda limpieza de texto eliminando los signos de puntuación y borramos las frases con una longitud menor de 10. En la función se ha añadido un retardo que sirve para no saturar al servidor.
Ahora con esta función realizamos un bucle que lea distintas fechas y nos genere un data.frame con las frases de las vistas por fecha de analisisydecision.es:
anios = ['2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017']
meses = ['11']
df_list = []
for i in anios:
for j in meses:
try:
m = extrae(i, j)
df_list.append(m)
except:
print(f"Error en {i}/{j}")
df = pd.concat(df_list)
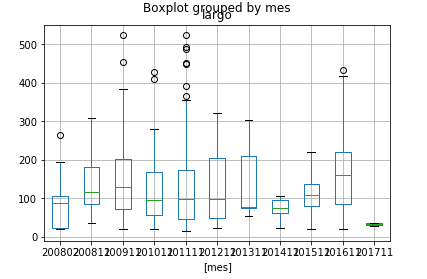
En este punto, pediros que no ejecutéis el bucle entero porque el servidor os echará de la web; a mí me ha saltado el firewall en repetidas ocasiones y de nada ha servido que haya puesto retardos. Creo que me ha permitido un máximo de 24 descargas. En cualquier caso, sólo descargamos unos meses y podemos hacer un boxplot:
import matplotlib.pyplot as plt
df.boxplot(column='largo', by='mes')
plt.show()
Vemos que no parece que las redes sociales estén afectando a la longitud de mis frases… yo diría que sí…